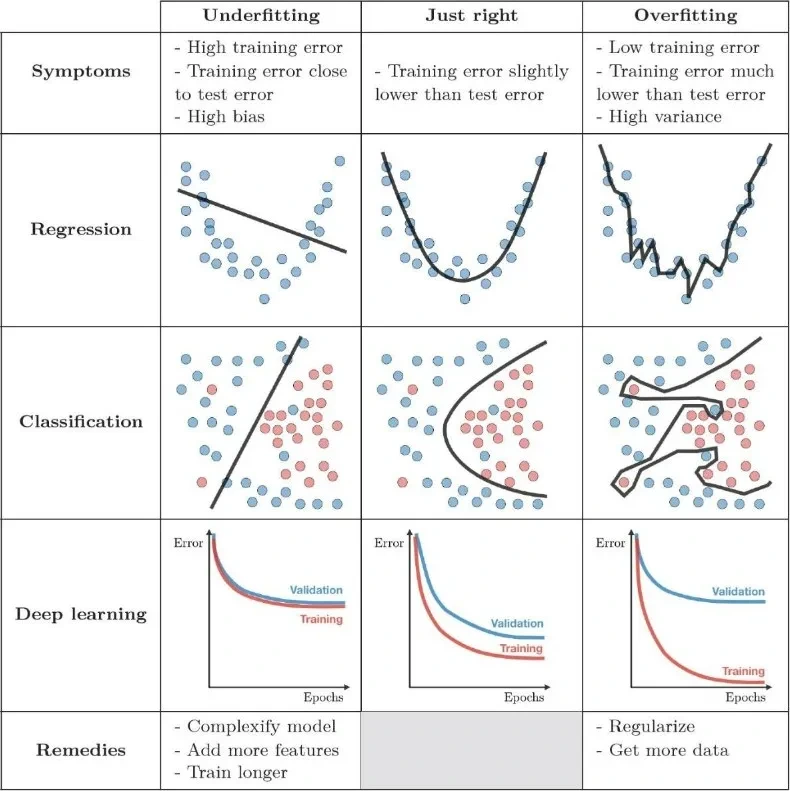
모델 학습(ML) 시 편향(bias)와 분산(Variance)은 중요한 오류 요소이다. 편향(Bias)이란?모델이 학습데이터를 단순화 하여 학습하는 정도를 의미한다. 편향이 높은 경우에 모델이 데이터를 충분히 설명하지 못하여, 일반화 성능이 떨어지는 '과소적합(underfitting)'상태가 될 수 있다. 추정 결과가 한 쪽으로 치우치는 경향을 보임에 따라서 발생하는 오차이다. 예를 들어, 선형 모델을 아주 복잡한 데이터에 적용한다면 데이터의 복잡성을 충분히 방영하지 못해 높은 편향을 나타낼수 있다. 분산(Variance)이란?분산은 모델이 학습 데이터의 노이즈에 민감하게 반응하여 학습된 정도를 나타내고 분산이 높은 경우에 모델이 학습 데이터에 과하게 맞춰져, 다른 유형의 데이터에 대해서 예측 정확도가..