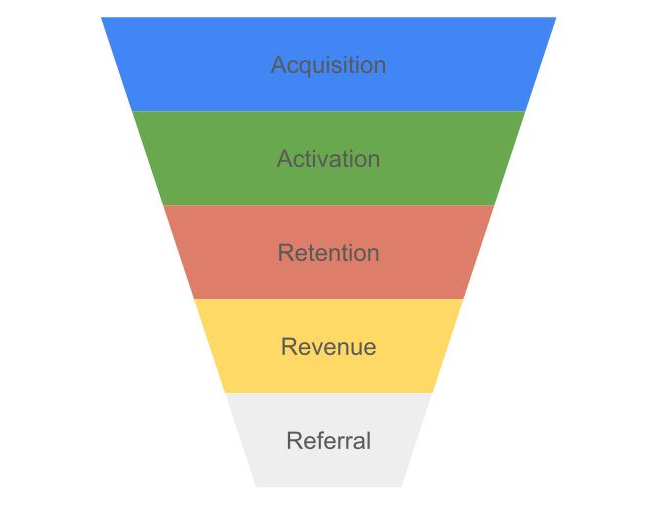
금주의 위클리페이퍼의 주제는 3가지이다. 1. AARRR 프레임워크(취득, 활성화, 유지, 수익 창출, 추천)와 리텐션 개념을 설명해 주세요. Funnel 분석과의 연관성을 설명해 주세요. 2. 코호트와 세그먼트의 차이점은 무엇인가요? 3. RFM 분석(Recency, Frequency, Monetary value)이란 무엇이며, 이를 통해 고객을 어떻게 세분화할 수 있는지 설명해 주세요. 각 요소의 중요성을 설명해 주세요. AARRR 프레임워크와 리텐션 개념ARRRR 모델(퍼널)은 제품 중심 기업과 스타트업에서 유용하게 이용되는 비즈니스 분석 프레임으로, 제품의 운영 현황을 신속하게 파악하고 비즈니스 목표와 마케팅 전략을 세워서 수익창출에 사용 할 수 있다. AARRR 모델 또는 해적지표라고 불리고,..