모델 학습(ML) 시 편향(bias)와 분산(Variance)은 중요한 오류 요소이다.
편향(Bias)이란?
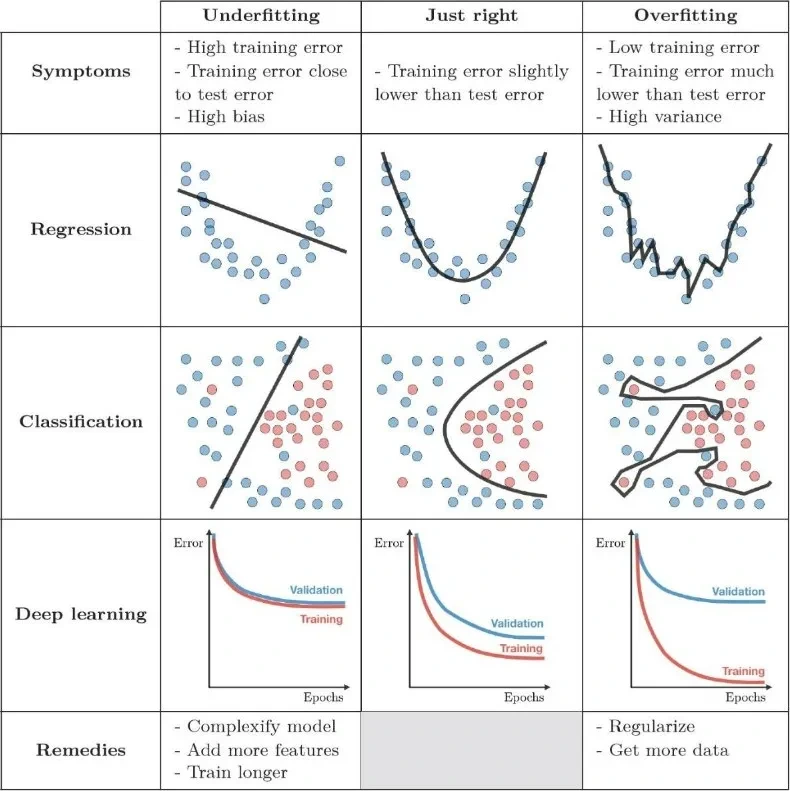
모델이 학습데이터를 단순화 하여 학습하는 정도를 의미한다. 편향이 높은 경우에 모델이 데이터를 충분히 설명하지 못하여, 일반화 성능이 떨어지는 '과소적합(underfitting)'상태가 될 수 있다. 추정 결과가 한 쪽으로 치우치는 경향을 보임에 따라서 발생하는 오차이다. 예를 들어, 선형 모델을 아주 복잡한 데이터에 적용한다면 데이터의 복잡성을 충분히 방영하지 못해 높은 편향을 나타낼수 있다.
분산(Variance)이란?
분산은 모델이 학습 데이터의 노이즈에 민감하게 반응하여 학습된 정도를 나타내고 분산이 높은 경우에 모델이 학습 데이터에 과하게 맞춰져, 다른 유형의 데이터에 대해서 예측 정확도가 떨어지는 '과적합(Overfitting)' 상태가 될 수 있다. 변량(데이터)들이 퍼저있는 정도를 의미한다. 복잡한 모델일수록 분산이 높아질 가능성이 높다.
편향과 분산의 트레이드 오프(Trade-off)
편향과 분산은 상충 관계에 놓여져 있다. 즉, 모델의 복잡도가 증가된다면 편향이 줄어드는 대신 분산이 높아지는 경향이 있고, 반대로 복잡도가 낮아지면 편향이 늘어나는 대신 분산이 적어지는 경향을 보이게 된다. 이러한 특성 때문에 최적의 모델을 위해서 적절한 편향과 분산의 균형을 맞춰야 한다. 또한 편향과 분산에서의 과소적합과 과적합을 줄이기 위해서는 다양한 방법을 시도해야 하는데, 과소적합(Underfitting)의 경우에는 feature수를 증가, 데이터에서의 노이즈 제거, 모델의 복잡성을 늘리는 방법으로 해결이 가능하고, 과적합(Overfitting)의 경우 모델이 복잡성을 줄이거나, 학습 데이터의 수를 늘리기, batch normalization과 같은 방법을 사용해야 한다.
'Codeit Sprint > Weekly_Paper' 카테고리의 다른 글
| 위클리 페이퍼 #14 - GROUP BY와 HAVING 절 (1) | 2024.11.17 |
|---|---|
| 위클리 페이퍼 #12 - K-폴드 교차검증 (0) | 2024.10.27 |
| 위클리 페이퍼 #11 - 손실함수(Loss function) (0) | 2024.10.18 |
| 위클리 페이퍼 #11 - 지도학습과 비지도 학습 (0) | 2024.10.18 |
| 위클리 페이퍼 #10 - A/B Test, Event Taxonomy(이벤트 데이터 로그 설계) (3) | 2024.10.10 |